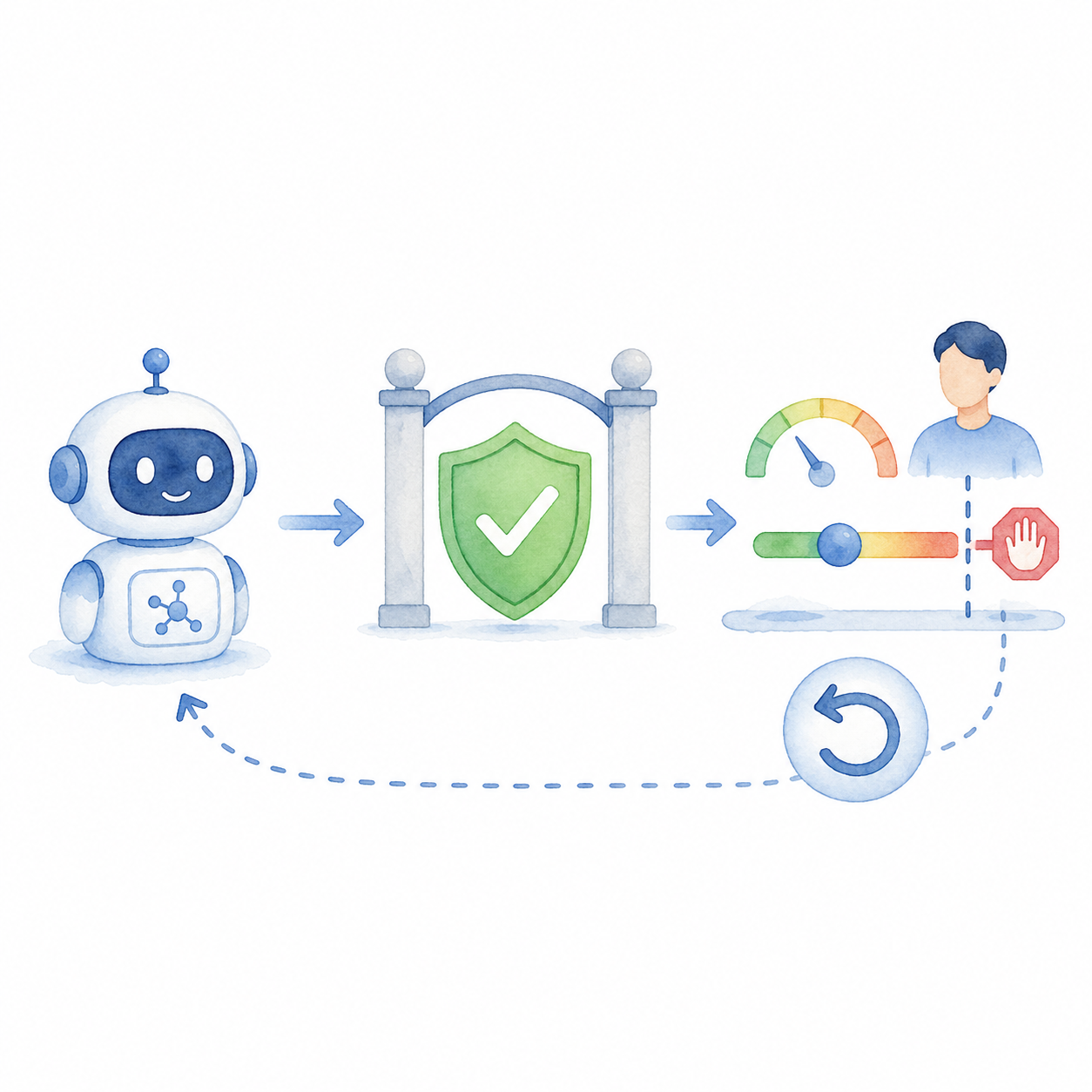
AI 에이전트 운영 통제는 무엇부터 설계해야 할까 2026-04-27 작성자: guguuu AI 에이전트 운영에서 approval point, action limit, rollback path를 어떻게 설계할지 정리합니다.
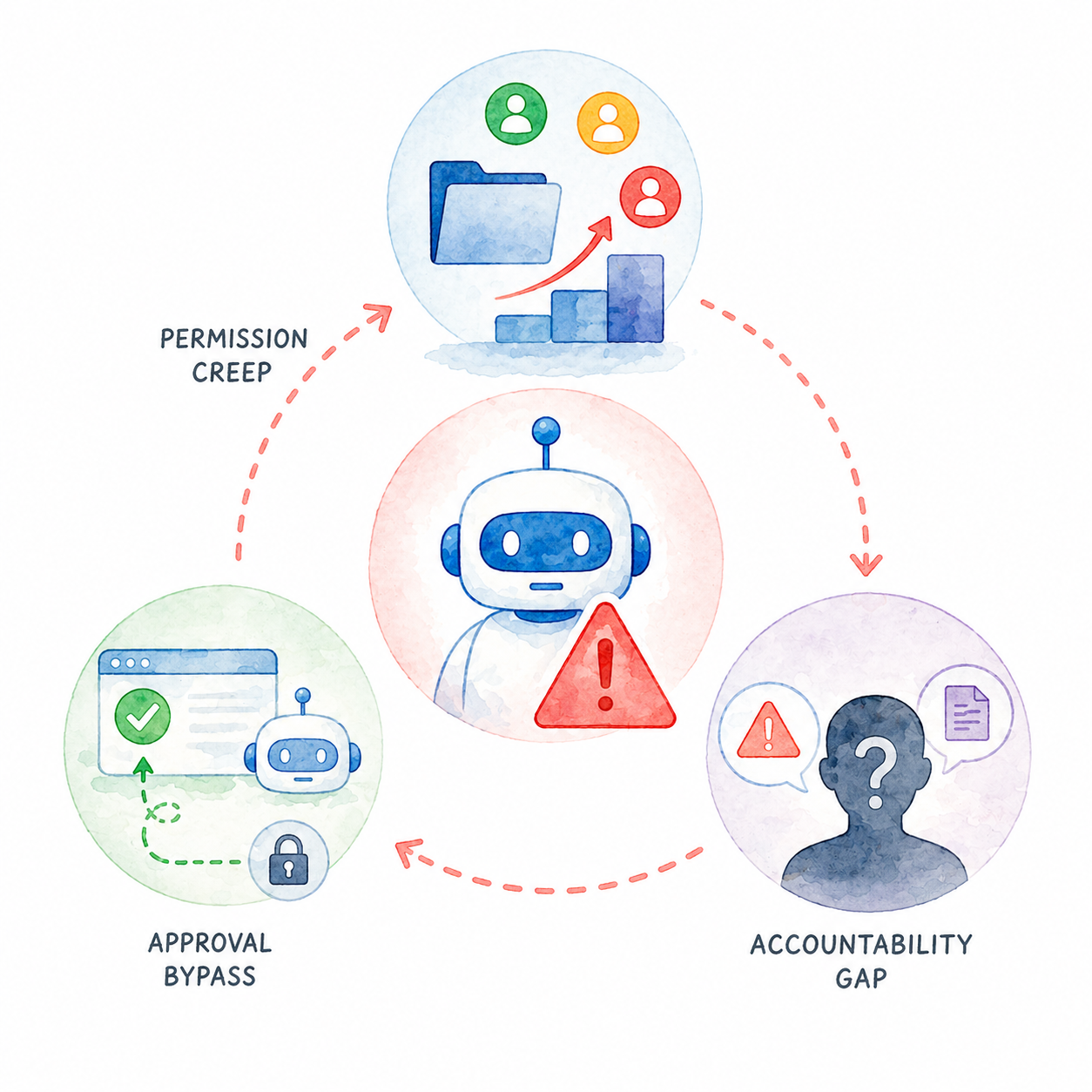
AI 에이전트 권한 문제는 어디서 먼저 흔들릴까 2026-04-27 작성자: guguuu AI 에이전트 권한 문제가 permission creep, 승인 우회, 책임 공백에서 어떻게 발생하는지 진단합니다.